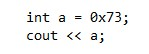Pytanie 1
W jaki sposób definiuje się konstruktor kopiujący w ramach klasy?
A. Generuje nowy obiekt klasy bez przypisywania wartości
B. Inicjuje obiekt klasy na podstawie klasy dziedziczącej
C. Tworzy nowy obiekt jako wierną kopię innego obiektu
D. Generuje nowy obiekt i usuwa wcześniejszy
Tworzenie nowego obiektu bez przypisania wartości to zadanie domyślnego konstruktora, który inicjalizuje obiekt, ale nie kopiuje stanu innego obiektu. Tworzenie obiektu na podstawie klasy pochodnej to proces dziedziczenia, a nie kopiowania – w tym przypadku tworzona jest nowa instancja klasy dziedziczącej, ale nie kopiowany jest stan innego obiektu. Usunięcie obiektu i stworzenie nowego nie jest zadaniem konstruktora kopiującego – za usuwanie odpowiada destruktor, który działa automatycznie podczas niszczenia obiektów.