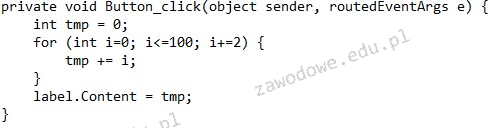
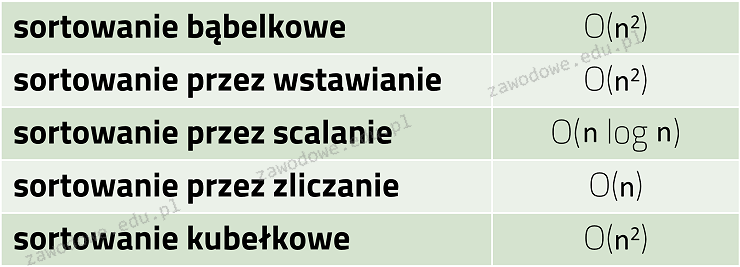
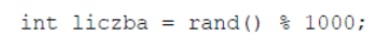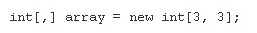Pytanie 1
Który z wymienionych typów danych należy do typu logicznego?
A. float
B. char
C. int
D. bool
Typ danych 'bool' (boolean) jest typem logicznym, który przechowuje jedną z dwóch wartości: 'true' lub 'false'. Typy logiczne są nieodłącznym elementem programowania, ponieważ umożliwiają implementację warunków i pętli sterujących przepływem programu. Typ 'bool' znajduje zastosowanie w praktycznie każdym języku programowania, w tym C++, Java, Python i C#. Operacje logiczne, takie jak 'AND', 'OR' i 'NOT', opierają się na wartościach typu 'bool', co czyni je podstawą dla algorytmów decyzyjnych i strukturalnych. Zastosowanie typów logicznych zwiększa czytelność kodu i pozwala na efektywne zarządzanie warunkami logicznymi.