Pytanie 1
Która z wymienionych metod jest najodpowiedniejsza do wizualizacji procesu podejmowania decyzji?
A. Schemat blokowy
B. Lista kroków
C. Drzewo decyzyjne
D. Pseudokod
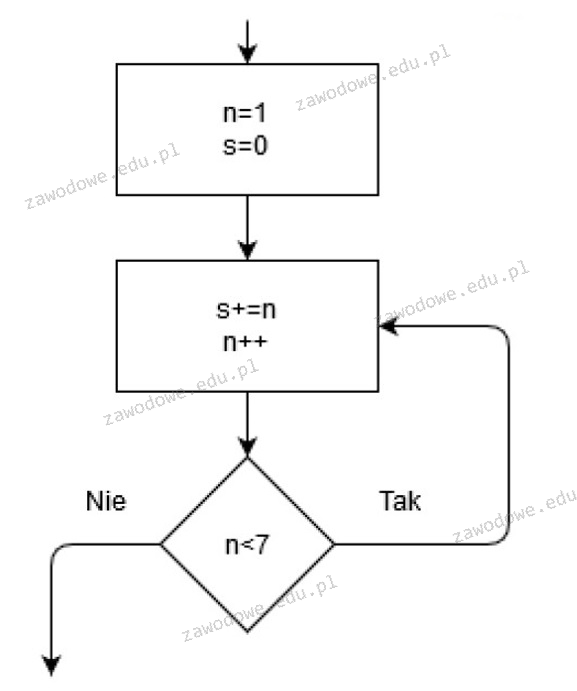
Schemat blokowy to jedna z najlepszych metod wizualnego przedstawienia procesu decyzyjnego. Umożliwia graficzne odwzorowanie przepływu operacji i decyzji, co czyni go niezwykle przydatnym narzędziem w analizie i projektowaniu algorytmów. Dzięki użyciu różnych kształtów (np. prostokątów dla operacji, rombów dla decyzji) schemat blokowy pozwala jasno i czytelnie przedstawić logikę działania programu lub systemu. Jest szeroko stosowany w inżynierii oprogramowania, zarządzaniu projektami oraz nauczaniu podstaw algorytmiki. Pozwala zidentyfikować potencjalne błędy i optymalizować procesy jeszcze przed rozpoczęciem implementacji.