Pytanie 1
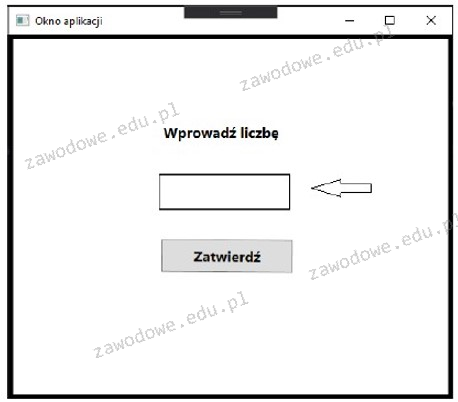
Które z wymienionych opcji wspiera osoby niewidome w korzystaniu z witryn internetowych?
A. Zmiana rozdzielczości ekranu
B. Umożliwienie modyfikacji czcionki
C. Ograniczenie liczby grafik na stronie
D. Implementacja czytnika ekranu (screen reader)
Dodanie czytnika ekranu (screen reader) jest kluczowym rozwiązaniem, które znacząco ułatwia osobom niewidomym i słabowidzącym korzystanie z serwisów internetowych. Czytniki ekranu to oprogramowanie przekształcające tekst na stronie internetowej na mowę, co pozwala użytkownikom na interakcję z treścią dostępną w internecie. Technologia ta opiera się na standardach dostępności, takich jak WCAG (Web Content Accessibility Guidelines), które zalecają projektowanie stron przyjaznych dla osób z różnymi niepełnosprawnościami. Przykładem działania czytnika ekranu może być program JAWS, który umożliwia użytkownikom nawigację po stronach internetowych poprzez komendy klawiaturowe oraz odczytywanie treści na głos. Dzięki czytnikom ekranu, osoby niewidome mają możliwość dostępu do informacji, komunikacji oraz interakcji w sieci, co wpisuje się w ideę cyfrowej inkluzji i równości szans. Wprowadzenie czytnika ekranu na stronie internetowej to nie tylko techniczne wsparcie, ale również wyraz odpowiedzialności społecznej, mający na celu zapewnienie, że wszyscy użytkownicy mają równe prawo do korzystania z zasobów w sieci.