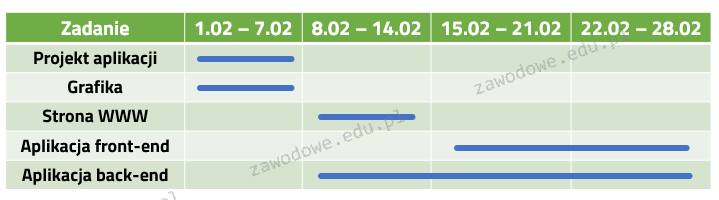
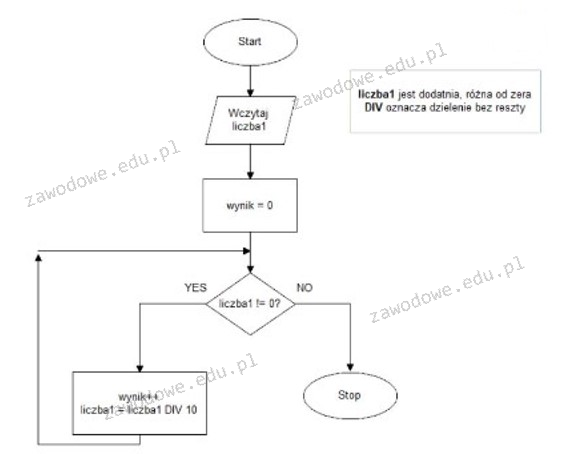
Pytanie 1
Celem zastosowania wzorca Obserwator w tworzeniu aplikacji WEB jest
A. informowanie obiektów o modyfikacji stanu innych obiektów
B. dostosowanie interfejsu użytkownika do różnych typów odbiorców
C. monitorowanie interakcji użytkownika i wysyłanie wyjątków
D. zarządzanie funkcjami synchronicznymi w kodzie aplikacji
Wzorzec Obserwator, znany również jako Observer, jest fundamentem programowania związanego z aplikacjami webowymi, szczególnie w kontekście architektury MVC (Model-View-Controller). Jego głównym celem jest umożliwienie obiektom (zwanym obserwatorami) subskrybowania zmian stanu innych obiektów (zwanych obserwowanymi). Kiedy stan obiektu obserwowanego ulega zmianie, wszystkie powiązane obiekty obserwujące są automatycznie powiadamiane o tej zmianie. Takie podejście jest szczególnie użyteczne w aplikacjach, gdzie interfejs użytkownika musi być dynamicznie aktualizowany w odpowiedzi na zmiany danych, na przykład w przypadku aplikacji do zarządzania danymi w czasie rzeczywistym. Przykładem może być aplikacja czatu, w której nowe wiadomości są automatycznie wyświetlane użytkownikom, gdy tylko są dodawane przez innych. Wzorzec ten jest również zgodny z zasadami SOLID, zwłaszcza z zasadą otwarte-zamknięte, umożliwiając rozwijanie aplikacji bez konieczności modyfikowania istniejących klas. W różnych technologiach webowych, takich jak JavaScript z użyciem frameworków takich jak React czy Angular, wzorzec Obserwator jest implementowany przez mechanizmy takie jak stany komponentów, co przyczynia się do lepszej organizacji kodu i zachowania jego czytelności.