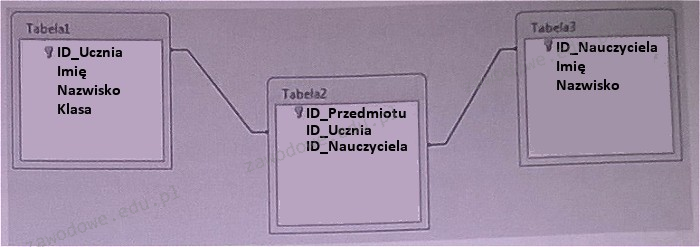
Pytanie 1
W języku HTML stworzono definicję tabeli. Który z rysunków ilustruje jej działanie?
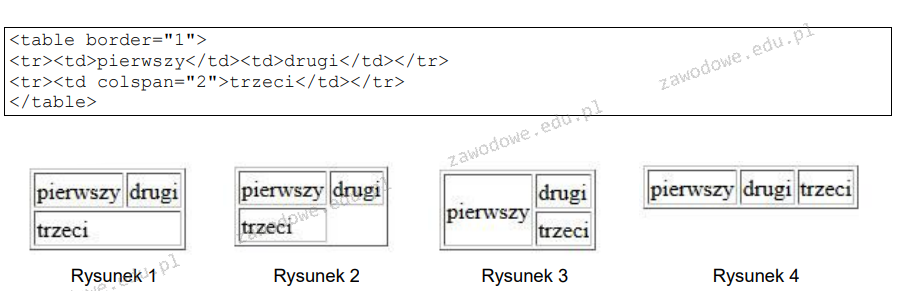
A. Rysunek 3
B. Rysunek 1
C. Rysunek 2
D. Rysunek 4
Prawidłowa odpowiedź to Rysunek 1 ponieważ odwzorowuje on strukturę tabeli opisaną w kodzie HTML zaprezentowanym w pytaniu. Kod HTML przedstawia tabelę z dwoma wierszami. Pierwszy wiersz zawiera dwie komórki z tekstami 'pierwszy' i 'drugi'. Drugi wiersz posiada jedną komórkę z tekstem 'trzeci' która zajmuje szerokość dwóch kolumn dzięki zastosowaniu atrybutu colspan=2. Właśnie ta cecha sprawia że drugi rysunek jest poprawny gdyż w nim komórka z tekstem 'trzeci' rozciąga się na szerokość dwóch kolumn tabeli. Takie podejście jest zgodne z zasadami projektowania tabel w HTML gdzie atrybut colspan pozwala na łączenie kolumn co jest szczególnie przydatne przy tworzeniu złożonych układów danych w tabelach. Dzięki zastosowaniu tego atrybutu można efektywnie zarządzać szerokością komórek i ich położeniem co zwiększa elastyczność w projektowaniu układów na stronach internetowych. Warto zwrócić uwagę na fakt że użycie atrybutu 'border' z wartością 1 powoduje wyświetlenie widocznej ramki co jest dobrze zilustrowane na Rysunku 1. Zrozumienie i umiejętne zastosowanie takich technik w projektowaniu stron jest kluczowe dla tworzenia przejrzystych i funkcjonalnych interfejsów użytkownika.