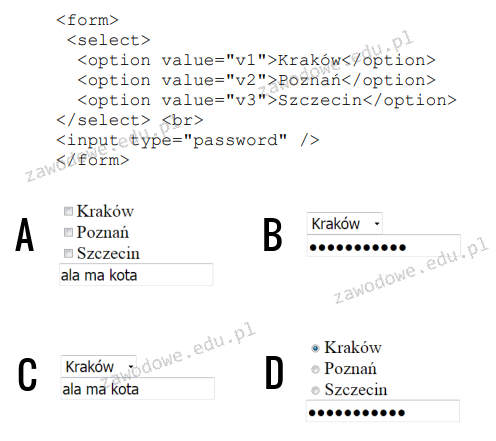
Pytanie 1
Podczas testowania skryptu JavaScript można w konsoli wyświetlać obecnie przechowywane wartości zmiennych przy użyciu funkcji
A. console.warn()
B. console.error()
C. console.log()
D. console.count()
Funkcje console.count(), console.warn() i console.error() mają różne zastosowania, które nie są odpowiednie do prostego wyświetlania wartości zmiennych. console.count() jest używana do zliczania, ile razy została wywołana w danym kontekście, co może być przydatne w niektórych przypadkach, ale nie służy do prezentacji bieżących wartości zmiennych. Użycie tej metody może prowadzić do nieporozumień, ponieważ nie umożliwia użytkownikowi bezpośredniego przeglądania wartości w tradycyjny sposób. console.warn() generuje komunikaty ostrzegawcze, a jej celem jest zwrócenie uwagi na potencjalne problemy w kodzie. Ta funkcja, mimo że może przekazywać informacje o stanie aplikacji, nie jest przeznaczona do monitorowania konkretnych wartości zmiennych. Z kolei console.error() służy do zgłaszania błędów, co jest kluczowe w identyfikacji problemów, ale także nie dostarcza bieżących informacji o zmiennych. Używanie tych metod w kontekście debugowania zmiennych może prowadzić do błędnych wniosków, ponieważ nie dostarczają one pełnego obrazu danych. Programiści często wpadają w pułapkę myślenia, że wszelkie komunikaty w konsoli są równoważne z efektywnym debugowaniem, co jest mylnym podejściem. Kluczowe jest zrozumienie, że każda z tych funkcji ma swoje specyficzne zadanie i nie powinny być one stosowane zamiennie z console.log(), która jest dedykowana do prostego i przejrzystego logowania wartości zmiennych.